

 TRENDING
TRENDING
Learn what an AI receptionist is, how it works, its benefits, top features, and the best AI receptionist software for businesses in 2026.
Latest articles
Learn what an AI receptionist is, how it works, its benefits, top features, and the best AI receptionist software for businesses in 2026.
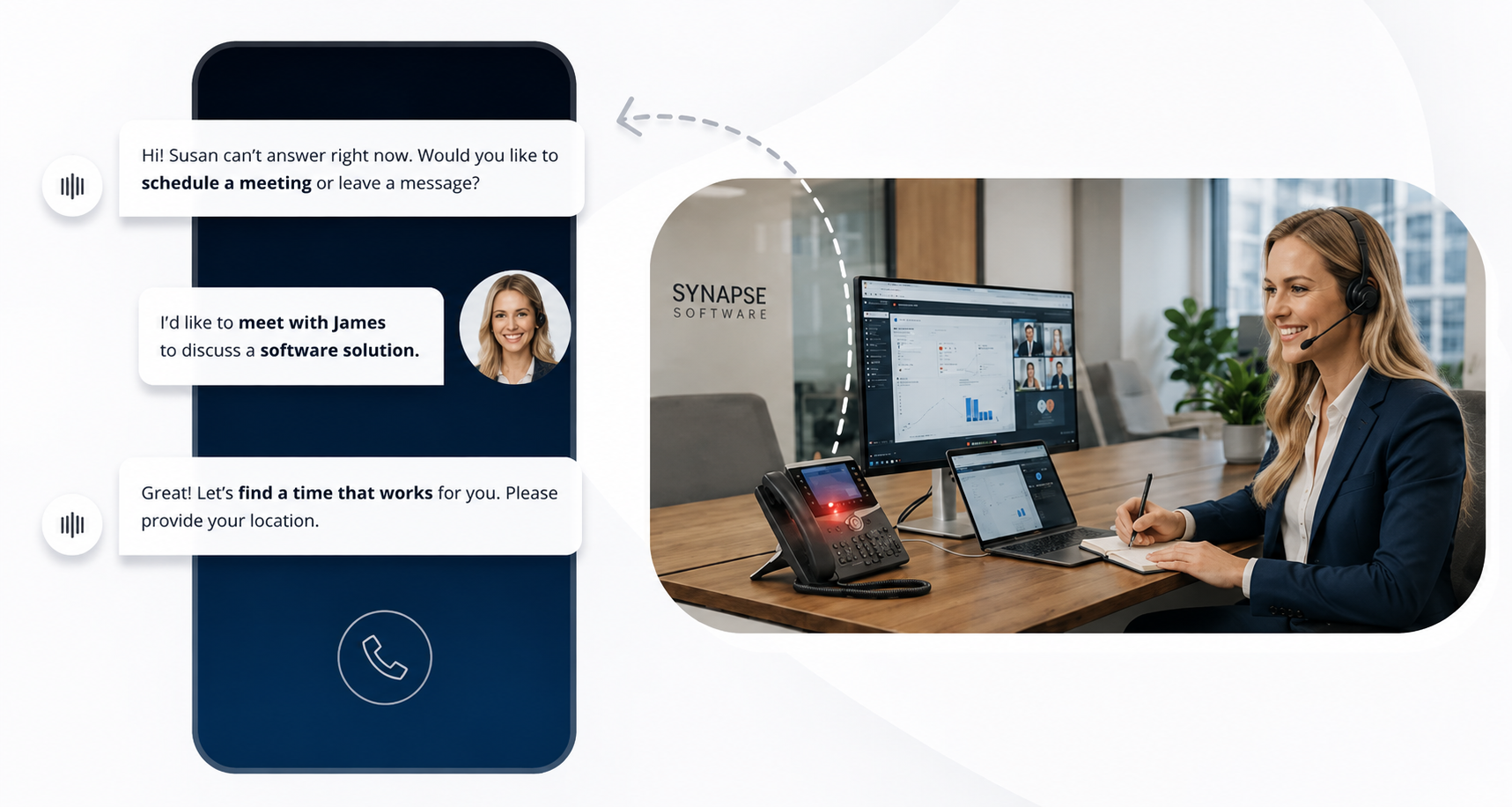
Missed calls cost bookings. See how an AI voice agent for appointment scheduling qualifies callers and confirms bookings live, no callbacks needed.
_.jpg)
Explore the best AI voice agent platforms for automating phone calls, qualifying leads, and booking appointments with conversational AI in 2026.

Discover how AI helps RIAs automate client scheduling, inbound calls, and administrative work to improve efficiency and scale advisory firms.

Learn how RIA firms scale client meetings with AI scheduling, automated workflows, and smarter operations to grow AUM without increasing headcount.

Learn what a Registered Investment Advisor (RIA) is, how RIAs work, fiduciary duties, fee structures, regulations, and how to choose the right RIA firm.

Build the ideal RIA tech stack for 2026. Compare the best CRM, financial planning, AI scheduling, compliance, and portfolio management tools for advisors.
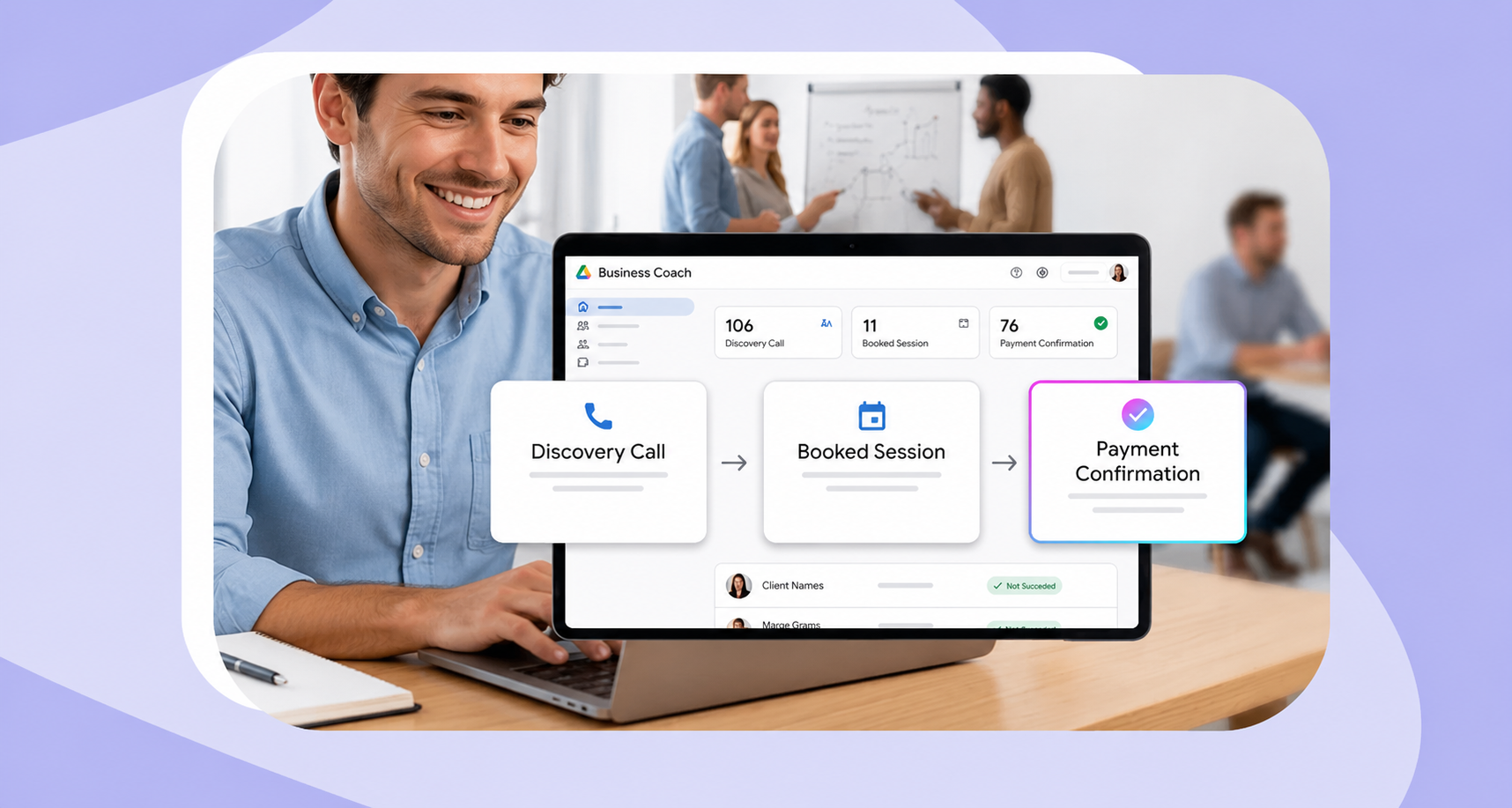
Configure your AI voice assistant to screen, qualify, and book coaching clients automatically, without losing your practice's voice or values.
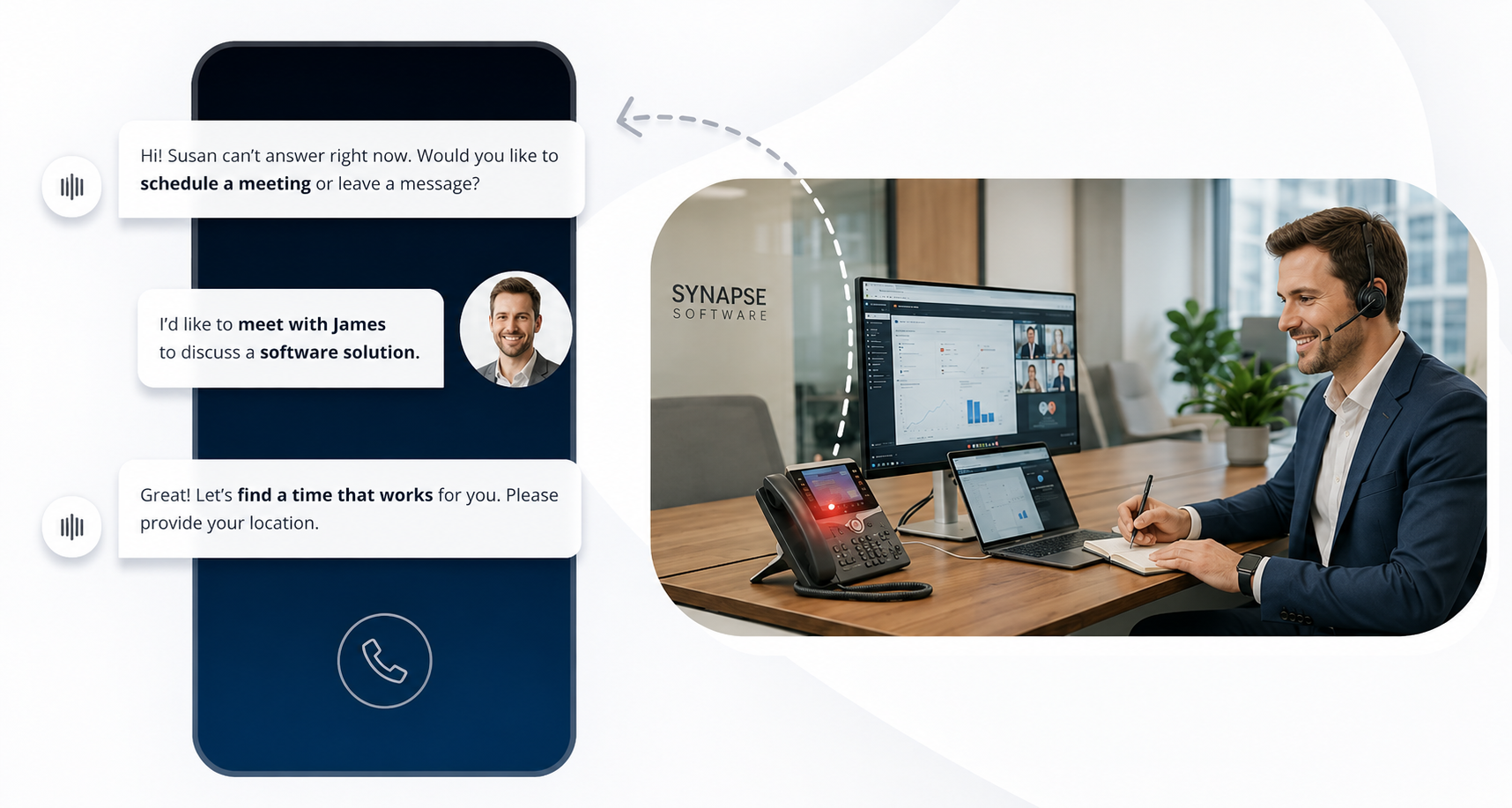
AI-powered voice assistants explained: top features, real-world use cases, and the best tools for business in 2026. Compare platforms and pricing.

Learn how AI agents in finance automate compliance, underwriting, fraud detection, and advisor workflows to boost productivity and growth.

Discover how AI is transforming investment banking with automated due diligence, financial modeling, deal sourcing, and client scheduling workflows.

Explore how AI is transforming wealth management with smarter client engagement, automated workflows, compliance monitoring, and investment insights.

Looking for the best financial advisor productivity tools? Compare the top platforms for scheduling, CRM, compliance, and automation.
For small businesses with no backup, every missed call is a miss. Here are the 5 best AI phone agents for small businesses in 2026, matching your business.
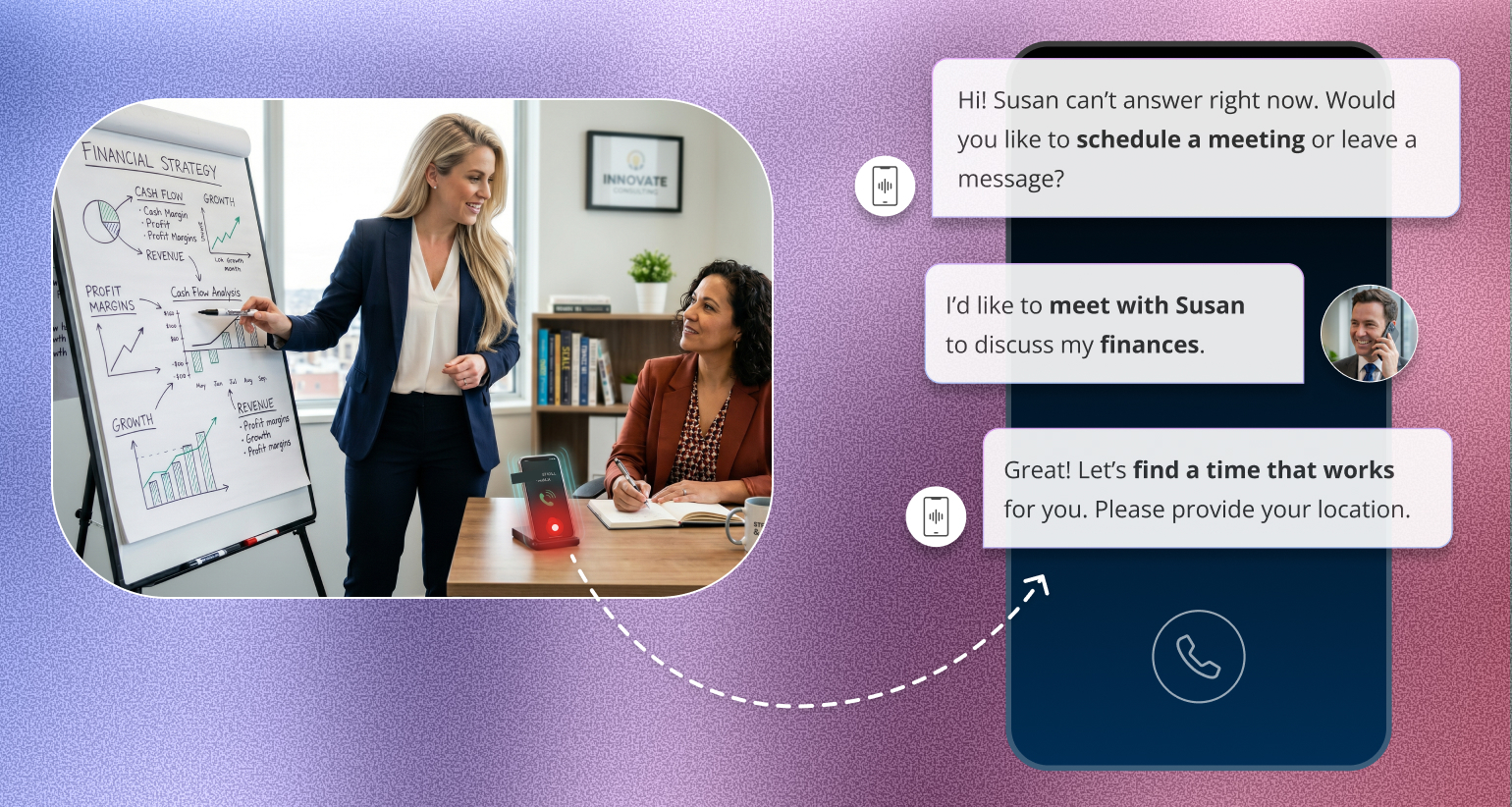
Learn how AI phone agents help financial advisors and coaches capture more leads, answer every call, and book appointments without missing opportunities.